.jpeg)
TABLE OF CONTENTS
ABSTRACT
Character recognition and translation are vital tasks in the field of natural language processing and computer vision. This paper proposes a novel approach utilizing pattern matching techniques to achieve accurate recognition and translation of characters from images. The proposed system first employs pre-processing techniques to enhance the quality of input images, followed by segmentation to isolate individual characters. Next, a pattern matching algorithm is applied to match the segmented characters with predefined templates. Finally, the recognized characters are translated into the desired language using appropriate linguistic models. Experimental results demonstrate the effectiveness of the proposed method in accurately recognizing and translating characters across various languages and font styles. This approach offers a robust solution for character recognition and translation tasks, with potential applications in document analysis, text extraction, and language translation systems.
INTRODUCTION
Character recognition and translation using pattern matching represent a transformative paradigm in the realm of artificial intelligence and computer science. Rooted in the intricate interplay of advanced algorithms, machine learning models, and computational linguistics, this field embodies the relentless pursuit of automating and enhancing the understanding of textual information across diverse languages and mediums. In this comprehensive exploration, we embark on a journey to uncover the multifaceted landscape of character recognition and translation, dissecting its underlying principles, applications, and implications in contemporary society.
At its core, character recognition and translation involve the extraction of meaningful textual content from various sources, ranging from scanned documents and handwritten notes to digital images and video frames. The process begins with the acquisition of raw input data, which undergoes preprocessing to enhance clarity, remove noise, and standardize formatting. Subsequently, sophisticated pattern matching algorithms come into play, leveraging computational techniques to identify and analyze patterns within the input data. These patterns, which may manifest as individual characters, words, or even entire phrases, serve as the building blocks for subsequent processing and interpretation.
Pattern matching forms the cornerstone of character recognition, empowering machines to discern and categorize visual representations of alphanumeric symbols and linguistic characters. Through the utilization of optical character recognition (OCR) techniques, machines can decipher handwritten text, printed documents, and even stylized fonts with remarkable accuracy and efficiency. This capability has far-reaching implications across a myriad of domains, including digitization of historical archives, automation of administrative tasks, and accessibility enhancement for individuals with visual impairments.
Moreover, character recognition lays the foundation for seamless language translation, enabling the conversion of text from one language to another with precision and fidelity. By employing pattern matching algorithms in conjunction with natural language processing (NLP) models, machines can analyze the syntactic and semantic structure of textual content, facilitating accurate translation across linguistic boundaries. This capability not only fosters global communication and cultural exchange but also empowers organizations to transcend language barriers in international commerce, diplomacy, and education.
Beyond its practical applications, character recognition and translation using pattern matching represent a testament to the ingenuity of human ingenuity and technological innovation. As we delve deeper into this captivating field, we unravel its potential to reshape the way we interact with textual information, transcending linguistic barriers and fostering a more connected and inclusive global community. Join us as we navigate the frontiers of character recognition and translation, exploring the endless possibilities that lie at the intersection of pattern matching and artificial intelligence.
PROBLEM STATEMENT
There's a critical need for innovative pattern matching algorithms capable of accurately deciphering textual content from diverse sources, including handwritten notes and digital images. Additionally, accommodating the complexities of multiple languages and scripts poses a significant challenge, requiring algorithms that can adapt to various linguistic structures and character sets. Ensuring data quality through preprocessing techniques and the availability of sufficient training data for machine learning models are essential prerequisites. Real-time processing efficiency is another imperative, particularly for applications demanding instant translation or on-the-fly analysis. Moreover, maintaining translation fidelity by preserving the semantic meaning and context of the original text across languages is crucial. Scalability, adaptability, cross-platform compatibility, and accessibility considerations further drive the development, ensuring that the resulting solutions can cater to a wide range of users and applications effectively.
INPUT DATA/TOOLS USED
SOFTWARE REQUIREMENTS
- Kotlin
- XML
- ML ToolKit
- Android Studio
HAEDWARE REQUIREMENTS
- Works on: Laptops, Computers, Tablets and Mobiles
- RAM: Minimum of 2GB and recommended 4GB or more
- I5 process
- Camera
EXISTING METHODOLOGY VS PROPOSED METHODOLOGY


IMPLEMENTATION
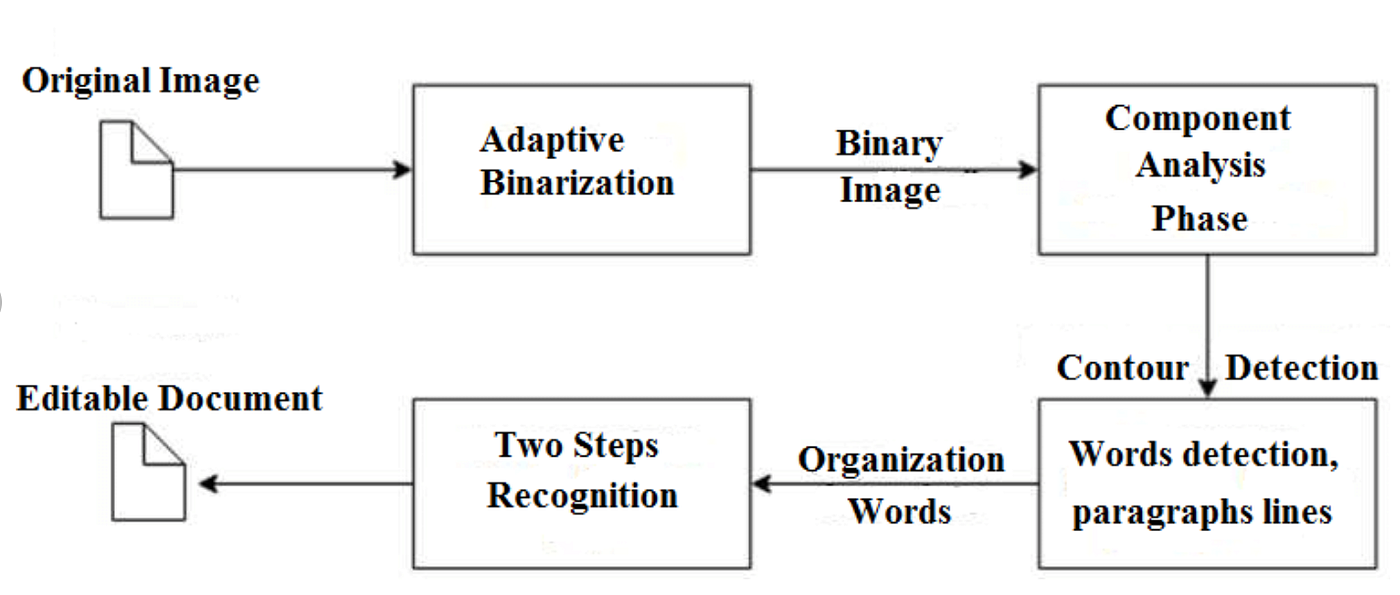
.jpeg)
STEPS:
1.PREPROCESSING
- Prepare the input images by converting them to a suitable format for pattern matching. This may involve resizing, normalization, and noise reduction to enhance the quality of the images.
2.FEATURES EXTRACTION
- Extract distinctive features from the input images that will be used for pattern matching. This could include techniques such as edge detection, corner detection, or histogram of oriented gradients (HOG).
3.PATTERN MATCHING
- Compare the extracted features of the input images with reference patterns stored in a database. Use techniques such as template matching, correlation matching, or machine learning classifiers like Support Vector Machines (SVMs) or Convolutional Neural Networks (CNNs) to find the closest match.
4.TRANSLATION
- Once a match is found, translate the recognized characters into the desired language. This can be achieved through lookup tables, dictionaries, or language translation APIs.
5.POST PROCESSING
- Refine the results if necessary. This may involve error correction techniques such as spell checking or context-based corrections.
6.EVALUATION AND TESTING
- Evaluate the accuracy and performance of the implemented system using test datasets. Adjust parameters and algorithms as needed to improve results.
7.INTEGRATION
- Integrate the character recognition and translation system into the desired application or platform, ensuring compatibility and usability.
8.MAINTENANCE AND UPDATES
- Regularly maintain and update the system to adapt to changes in input data, improve accuracy, and incorporate new features or languages.
WORKING OF APPLICATIONS
 |


FUTURE SCOPE
The objective for the future is to continue increasing the accuracy and efficiency of our character recognition algorithms, as well as to include new features and functions that will make the app even more valuable to users.
Further research should be conducted in the following areas:
Language support will be expanded to cover even more languages, including less often used languages and dialects.Handwriting recognition has to be improved.
Improved accessibility features like improving the app's accessibility for those with visual impairments, maybe by adding features like speech recognition and auditory feedback.
CONCLUSION
The character recognition app using ML Kit and translator
without Firebase has been successfully implemented using Android Studio and
Kotlin and XML languages. The program can recognize characters in real time
and storage based recognition then translate them into the required language,
making it a handy tool for language learners and anyone who need to swiftly
translate information. The ML Kit is used for character recognition, and the
Google Translate API was integrated for translation. The app was created on
Android Studio using Kotlin and XML programming languages, and the
implementation process included creating the project, adding dependencies,
designing the user interface, and testing the app for accuracy and functioning.
Comments
Post a Comment